
Fabian-Robert Stöter
Head of Research at Audioshake.ai, Frankfurt, Germany
Music Processing
I have a background in digital signal processing (DSP) and have worked on a wide range of audio and related tasks, including speech- and audio processing, music analysis and music information retrieval.
Audio-AI
I have a profound understanding of deep audio-ml. I am specifically interested in the tasks of source count estimation and audio source separation. I am leading the research team at Audioshake.ai that created the best performing music separation and lyric transcription models.
Eco-ML
I was involved in Pl@ntNet as part of Cos4Cloud 🇪🇺 citizen science project. I was also working on ML for ecoacoustics, analyzing sounds of 🦓 using mobile audio loggers.
# About me
 Since 2021, I'm head of research at audioshake.ai (opens new window) working on music-ml research. Before, I was a postdoctoral researcher at the Inria and University of Montpellier (opens new window), France. I did my Ph.D (Dr.-Ing.) at the International Audio Laboratories Erlangen (opens new window) (is a joint institution of Fraunhofer IIS (opens new window) and FAU Erlangen-Nürnberg (opens new window)) in Germany supervised by Bernd Edler (opens new window). My dissertation titled «Separation and Count Estimation for Audio Sources Overlapping in Time and Frequency» can be viewed here (opens new window). Before, I graduated in electrical engineering / communication engineering from the University of Hannover, Germany (opens new window). An extended CV is available here (opens new window).
Since 2021, I'm head of research at audioshake.ai (opens new window) working on music-ml research. Before, I was a postdoctoral researcher at the Inria and University of Montpellier (opens new window), France. I did my Ph.D (Dr.-Ing.) at the International Audio Laboratories Erlangen (opens new window) (is a joint institution of Fraunhofer IIS (opens new window) and FAU Erlangen-Nürnberg (opens new window)) in Germany supervised by Bernd Edler (opens new window). My dissertation titled «Separation and Count Estimation for Audio Sources Overlapping in Time and Frequency» can be viewed here (opens new window). Before, I graduated in electrical engineering / communication engineering from the University of Hannover, Germany (opens new window). An extended CV is available here (opens new window).
# Current Research Interests
Deep learning on data hubs: I am interested multi-modal foundation models that can learn the relations between the different modalities to reconstruct or enhance missing or degraded data.
User-centered AI for audio data: I want to develop new methods and tools for users with domain knowledge to deliver interpretable audio models. Furthermore, evaluation of audio processing tasks is often done in a computational manner, due to the lack of expertise from signal processing researchers in organizing perceptual evaluation campaigns.
Ecological machine-learning: I want to play a role in reducing the carbon footprint of my work. Reducing the size of datasets speeds up training and therefore saves energy. Reducing the computational complexity of models is an active research topic, with strongly investigated ideas like quantization, pruning or compression. Inspired by current trends in differentiable signal processing, I want to convert deep models so that they can be deployed on edge devices.
# Press/Media Interviews
- 02/2023 "l'intelligence artificielle et du droit d'auteur", Radio-Canada (French) (opens new window)
- 12/2022 "Jahresrückblick und Vorausschau: KI Musik und Metaverse", Deutschlandfunk Kultur (German) (opens new window)
- 02/2022 "L'intelligence artificielle au profit des stems musicaux", Radio-Canada (French) (opens new window)
- 12/2021 "Recycling von Songs: Wie KI neue Musik generiert", Deutschlandfunk Kultur (German) (opens new window)
# Scientific Service
# Editing
- Journals: Topic Editor for ML-Audio for the Journal of Open Source Software (opens new window).
# Reviewing
- Journals: Journal of Open Source Software (opens new window),
IEEE Transaction in Audio, Speech and Language Processing (opens new window),Signal Processing Letters (opens new window), EURASIP (opens new window), - Conferences: ISMIR (opens new window),
ICASSP (opens new window), EUSIPCO (opens new window), DAFx (opens new window)
# Student Supervision
- Laura Ibáñez Martínez (opens new window), Master Student, Co-Supervision: Master thesis: "MIDI-AudioLDM: MIDI-Conditional Text-to-Audio Synthesis Using ControlNet on AudioLDM" Thesis (opens new window), Summer 2023
- Johannes Imort (opens new window), Master student, RWTH Aachen (Germany), Internship "Sound Activity Detection". Winter 2022
- Jinsung Kim (opens new window) and Yeong-Seok Jeong, Master students, Korea University, (Winter 2022/2023) Internship on "Unsupervised Music Separation" (Summer 2022).
- Michael Tänzer, PhD student, Fraunhofer IDMT (Germany), (Summer 2021), Internship on audio tagging.
- Lucas Mathieu (opens new window), Master student, AgroParistech (France), Master thesis "Listening to the Wild" (03/2020). Theoretical research on self-supervised learning using data from animal-born loggers (MUSE project (opens new window)). Lucas was accepted as a PhD student after master thesis.
- Clara Jacintho (opens new window) and Delton Vaz, Bachelor Thesis, PolyTech Montpellier (France), "Machine Learning for Audio on the Web" (12/2019). Research on web based separation architectures. Resulted in a paper submitted to the Web Audio Conference 2021 (opens new window).
- Wolfgang Mack (opens new window), Master Thesis (FAU Erlangen-Nürnberg, Germany), "Investigations on Speaker Separation using Embeddings obtained by Deep Learning", (05/2017), Wolfgang was accepted as PhD student after master thesis.
- Erik Johnson (opens new window), DAAD (opens new window) Research internship, (Carleton University, Canada), "Open-Source Implementation of Multichannel BSSEval in Python" (opens new window) (03/2014).
- Nils Werner (opens new window), Master Thesis, (FAU Erlangen-Nürnberg, Germany), "Parameter Estimation for Time-Varying Harmonic Audio Signals", (02/2014), Nils was accepted as PhD student after master thesis.
- Jeremy Hunt (opens new window), DAAD (opens new window) research internship, (Rice University, USA)
- Bufei Liu, Master, Research Internship (Shanghai University, China), 2014.
- Aravindh Krishnamoorty (opens new window), Master, Internship, 2014
- Ercan Berkan, Master Thesis, (Bilkent University, Turkey), "Music Instrument Source Separation", 3/2013
- Shujie Guo (opens new window), Master, Research Internship, (FAU Erlangen-Nürnberg, Germany)
# Teaching
# Graduate Programs
- 2024: Guest-Lecture: "Is music separation interesting in the age of generative AI?", Music Information Retrieval (MIR) program, Master-2, Telecom-ParisTech
- 2021: Guest-Lecture: Selected Topics in Deep Learning for Audio, Speech, and Music Processing (opens new window), Music Source Separation, University of Erlangen (Germany).
- 2020: Research Internship (opens new window) (Master, Stage 5), PolyTech Montpellier
- 2018, 2019: Introduction to Deep Learning, Master 2, PolyTech Montpellier
- 2016: Reproducible Audio Research Seminar (opens new window), University of Erlangen (Germany)
- 2014-2016: Multimedia Programming , Highschool Students, University of Erlangen (Germany)
- 2013-2016: Lab Course, Statistical Methods for Audio Experiments, Master Students, University of Erlangen (Germany) Course Material (opens new window).
# Talks
- 2023: Invited talk: "Music Source Separation: Is it solved yet?", ParisTech, Paris (France) Slides (opens new window)
- 2020: Invited talk at AES Symposium "AES Virtual Symposium: Applications of Machine Learning in Audio" (opens new window) titled "Current Trends in Audio Source Separation". Slides (PDF) (opens new window) Video (opens new window)
- 2019: Invited talk at a conference “Deep learning: From theory to applications” (opens new window) titled “Deep learning for music unmixing”. Video (opens new window) Slides
- 2019: Tutorial at EUSIPCO 2019 (opens new window): "Deep learning for music separation". Slides Website
- 2018: Tutorial at ISMIR 2019 (opens new window): "Music Separation with DNNs: Making It Work". Slides Website
# Other Ressources
- sigsep.io (opens new window) - Open ressources for music separation.
- awesome-scientific-python-audio (opens new window) - Curated list of python packages for scientific research in audio.
# Software
#  open-unmix Winner: Pytorch Global Hackathon 2019
open-unmix Winner: Pytorch Global Hackathon 2019
Open-Unmix, a deep neural network reference implementation (PyTorch (opens new window) and NNabla (opens new window)) for music source separation, applicable for researchers, audio engineers and artists. Open-Unmix provides ready-to-use models that allow users to separate pop music into four stems: vocals, drums, bass and the remaining other instruments.
Demo Separations on MUSDB18 (opens new window) Dataset:
Website/Demo Code Paper ANR Blog (french) Pytorch Hackathon
# CountNet
CountNet is a deep learning model that estimates the number of concurrent speakers from single channel speech mixtures. This task is a mandatory first step to address any realistic “cocktail-party” scenario. It has various audio-based applications such as blind source separation, speaker diarisation, and audio surveillance.
# musdb + museval
A python package to parse and process the MUSDB18 dataset (opens new window), the largest open access dataset for music source separation. The tool was originally developed for the Music Separation task as part of the Signal Separation Evaluation Campaign (SISEC) (opens new window).
Using musdb users can quickly iterate over multi-track music datasets. In just three lines of code a subset of the MUSDB18 is automatically downloaded and can be parsed:
import musdb
mus = musdb.DB(download=True)
for track in mus:
train(track.audio, track.targets['vocals'].audio)
Now, given a trained model, evaluation can simply be performed using museval
import museval
for track in mus:
estimates = predict(track) # model outputs dict
scores = museval.eval_mus_track(track, estimates)
print(scores)
# Hackathon Projects
# DeMask 1st Place
Event: 2020 PyTorch Summer Hackathon – Collaborators: Manuel Pariente, Samuele Cornell, Michel Olvera, Jonas Haag
DeMask is an end-to-end model for enhancing speech while wearing face masks — offering a clear benefit during times when face masks are mandatory in many spaces and for workers who wear face masks on the job. Built with Asteroid, a PyTorch-based audio source separation toolkit, DeMask is trained to recognize distortions in speech created by the muffling from face masks and to adjust the speech to make it sound clearer.
# git wig Winner
Event: 2015 Midi-Hackday Berlin, Collaborators: Nils Werner (opens new window), Patricio-Lopez Serrano (opens new window)

Why can't we have version on control for making music? In this hack, we merged git with a terminal based music sequencer, calling it git wig. We also created a suitable, diffable sequencer format to compose music. Finally, we realized git push by bringing this feature into a hardware controller.
# DeepFandom 1st Place
Event: 2016 Music Hackday Berlin. Collaborators: Patricio-Lopez Serrano (opens new window)
DeepFandom is a deep learning model that learns the Soundcloud comments and predicts what YOUR track could get as comments and where they are positioned on the waveform.
# Magiclock

Magiclock is an macOS application that uses haptic feedback (also called Taptic Engine™) to let you feel the MIDI clock beat from your Magic Trackpad.
# Other Software Contributions
- stempeg (opens new window) - read/write of STEMS multistream audio.
- trackswitch.js - A Versatile Web-Based Audio Player for Presenting Scientifc Results.
- webMUSHRA - MUSHRA compliant web audio API based experiment software.
- norbert - Painless Wiener filters for audio separation.
# Datasets
#  MUSDB18
MUSDB18
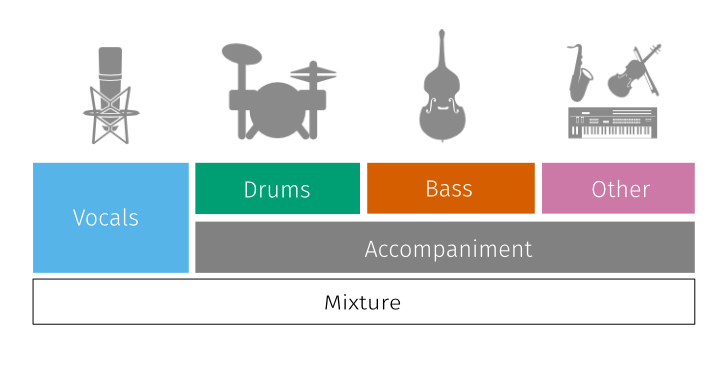
The musdb18 is a dataset of 150 full lengths music tracks (~10h duration) of different genres along with their isolated drums, bass, vocals and others stems. It is currently the largest, publicly available dataset used for music separation. MUSDB18 serves as a benchmark for music separation tasks.
# LibriCount

The dataset contains a simulated cocktail party environment of [0..10] speakers, mixed with 0dB SNR from random utterances of different speakers from the LibriSpeech CleanTest dataset.
All recordings are of 5s durations, and all speakers are active for the most part of the recording. For each unique recording, we provide the audio wave file (16bits, 16kHz, mono) and an annotation json file with the same name as the recording.
# Muserc
A novel dataset for musical instruments where we recorded a violin cello that includes sensor recordings capturing the finger position on the fingerboard which is converted into an instantaneous frequency estimate. We also included professional high-speed video camera data to capture excitations from the string at 2000 fps. All of the data is sample synchronized